
StepFun представила StepAudio 2.5 Realtime: голосовой AI с настраиваемыми персонажами
Китайская AI-лаборатория StepFun выпустила StepAudio 2.5 Realtime — голосовую модель в реальном времени, которая работает напрямую с аудио и поддерживает настраиваемые персонажи на китайском и английском языках. В отличие от систем, где речь сначала переводится в текст, а затем снова синтезируется в звук, StepAudio построена как сквозная модель «аудио на входе — аудио на выходе».
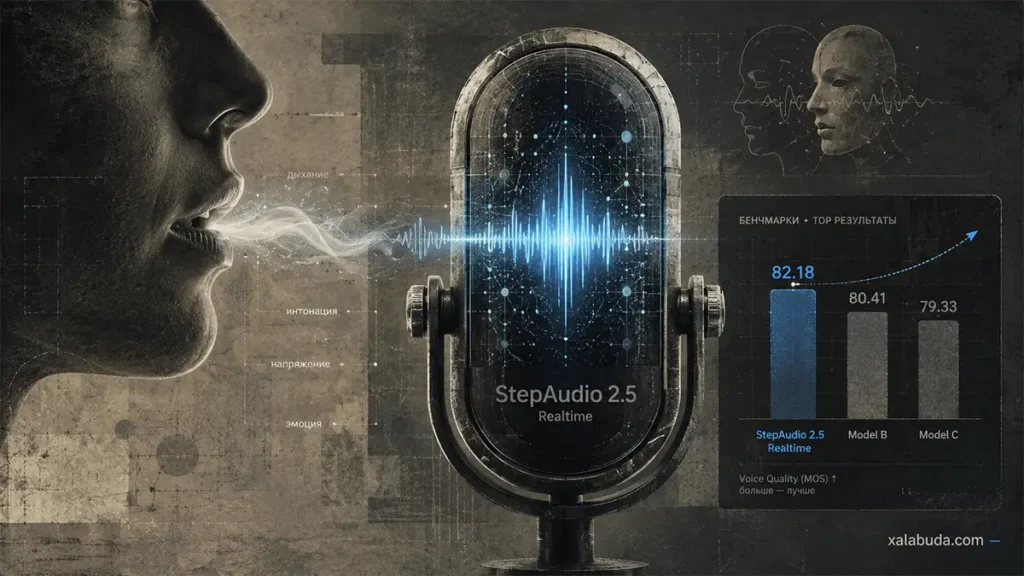
По заявлению StepFun, модель заняла первое место во всех пяти голосовых AI-бенчмарках, которые компания тестировала в апреле 2026 года. В сравнении фигурируют GPT Realtime 1.5, Gemini Live и DouBao Realtime. В тесте на понимание паралингвистических признаков StepAudio получила 82,18 балла против 80,46 у GPT Realtime 1.5, 58,05 у Gemini Live и 16,09 у DouBao Realtime.
В оценке людьми StepAudio набрала 80,41 балла, тогда как GPT Realtime 1.5 получил 68,01, а Gemini Live — 67,16. В тесте общего качества диалога результат StepAudio составил 86,36 балла против 81,60 у GPT Realtime 1.5. Эти цифры важны, но их стоит воспринимать с оговоркой: речь идёт о собственных бенчмарках StepFun, а не о независимом аудите.
Главный акцент StepFun делает не только на качестве речи, но и на устойчивости AI-персонажа в диалоге. StepAudio 2.5 Realtime обучали на наборе данных с миллионами профилей персонажей: основой стали более 10 000 вручную подготовленных описаний, которые затем расширили алгоритмически. Для удержания характера в длинных разговорах компания использовала RLHF, настроенный под ролевое взаимодействие.
Модель должна учитывать не только слова, но и акустические признаки речи: темп, эмоциональный тон и возрастные особенности голоса. Это приближает голосовых ассистентов к более естественному формату общения, где система реагирует не только на команду, но и на то, как она произнесена. Такой подход хорошо ложится в общий тренд практического применения AI, о котором уже шла речь в материале про переход OpenAI к прикладным сценариям.
StepFun также запускает AI-персону Xiao Yue и API для создания собственных персонажей. Компания основана в апреле 2023 года Jiang Daxin, который до этого 16 лет работал в Microsoft над Bing, Cortana и Azure Cognitive Services. По данным источника, StepFun уже привлекла около $1,7 млрд, а её текстовая модель Step 3.5 Flash насчитывает 196 млрд параметров.
Для рынка это ещё один сигнал, что конкуренция в голосовых AI-интерфейсах становится шире, чем противостояние OpenAI и Google. На фоне дискуссий о том, как Anthropic конкурирует с OpenAI в сегменте LLM, появление сильной голосовой модели от китайской StepFun показывает, что борьба постепенно смещается к персонализированным AI-собеседникам и аудиоинтерфейсам. Похожий интерес к локальным и встроенным AI-сценариям виден и в развитии Gemini Nano в Chrome.
Пока неизвестны цена StepAudio 2.5 Realtime, лимиты API, регионы доступности и условия коммерческого использования. Также не раскрыты точные технические характеристики модели, включая архитектуру, задержку ответа и требования к инфраструктуре.


